Federated Learning vs Centralized ML: Which Enterprise Model Fits Modern Data Strategy?
As enterprise AI programs mature, model design is no longer the only strategic decision that matters. Data architecture, governance, privacy, and operational feasibility now shape outcomes just as profoundly as algorithm choice. That is why Federated Learning vs Centralized ML has become an increasingly important comparison for organizations building machine learning systems in regulated, distributed, or data-sensitive environments.
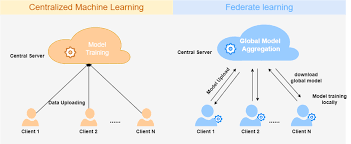
At a high level, centralized machine learning brings data into a common repository for training, while federated learning trains a shared model across decentralized data sources without moving the raw data itself. TensorFlow Federated and Google Cloud both describe federated learning in precisely these terms: collaborative model training on decentralized data, with local data retained at the source rather than pooled centrally.
Why Federated Learning vs Centralized ML Demands Greater Enterprise Attention
For years, machine learning development services, particularly centralized ML was the default operating model. It remains highly effective in many enterprise settings because it simplifies data preparation, model training, evaluation, and monitoring. Yet the assumptions behind centralized learning are under pressure.
Growing regulatory pressure, limits on international data transfers, deeply embedded institutional silos, and rising concern over personal and proprietary information are forcing organizations to reassess the assumption that all data should be consolidated in a single environment. NIST’s guidance on privacy-preserving federated learning presents this transition as a practical response to privacy, security, and governance demands.
This does not mean federated learning replaces centralized ML. It means the enterprise decision is no longer trivial.
Why Centralized ML Remains the Default in Many Enterprise Environments
Centralized ML remains the more straightforward option when an organization can legally and operationally aggregate data into one environment. It usually offers:
- Simpler data engineering and feature standardization.
- Easier experiment management and debugging.
- More direct model evaluation with a unified validation set.
- Lower coordination overhead during training.
- Faster iteration for many conventional use cases.
In practical terms, centralized ML is often the better fit when the organization already has strong data pipelines, permissive governance conditions, and a clear path to consolidating data at scale. Its operational simplicity is not a minor advantage. In enterprise delivery, simplicity often translates into shorter development cycles and cleaner accountability.
Why Federated Learning Matters in Distributed and Regulated Environments
Federated learning is designed for circumstances in which centralizing data is difficult, undesirable, or prohibited. It is described as a way to train shared models across many devices or servers without exchanging the underlying local data samples, while IBM similarly emphasizes privacy, confidentiality, regulatory compliance, and the practical challenge of moving data into a single training location.
That architecture is especially relevant in sectors such as healthcare, finance, telecom, public services, and multi-entity enterprise ecosystems, where data may be fragmented across institutions, geographies, or endpoints.
In those cases, federated learning can offer several advantages:
- reduced raw-data movement across environments.
- stronger alignment with data minimization principles.
- better suitability for edge and device-based learning scenarios.
- lower exposure of centralized repositories containing sensitive records.
- improved collaboration across organizations that cannot fully share datasets.
These benefits are real, but they should not be overstated. Federated learning does not eliminate privacy risk altogether. NIST and Google both note that privacy-preserving federated learning often requires additional techniques such as secure aggregation or differential privacy, because model updates themselves can still reveal information if the system is poorly designed.
The More Important Question for Enterprise Decision-Makers
The most useful way to frame Federated Learning vs Centralized ML is not to ask which approach is more advanced. The better question is which one fits the organization’s data reality, regulatory environment, and operating model.
A centralized approach is often superior when consolidation is feasible and speed matters. A federated approach becomes compelling when data cannot be moved easily, when collaboration must occur across boundaries, or when privacy-by-design is not optional. Neither model is universally better. Each reflects a different compromise between control, simplicity, privacy, and coordination.
What This Means for Enterprise AI Architecture and Long-Term Strategy
At its core, the comparison between Federated Learning and Centralized ML is a question of enterprise suitability. Centralized ML continues to offer the clearer path when data can be unified responsibly, development can proceed efficiently, and coordination burdens remain limited. Federated learning gains strategic importance when those advantages begin to erode, especially in settings marked by fragmented data, tighter governance, and heightened privacy demands.
Pattem Digital is where the discussion becomes less theoretical and more operational. The right decision is rarely about choosing the more advanced-sounding model; it is about selecting an architecture that fits the realities of scale, compliance, collaboration, and long-term delivery. Through Artificial Intelligence Development Services, enterprises can evaluate these trade-offs more clearly and build ML systems that are not only technically sound, but also aligned with the conditions in which they must perform.